

A framing for interpretability
A framing for interpretability
How I currently think of neural network interpretability

Note: These are my personal views, (and not of Anthropic, which I just joined today)
In this post, I will share my current model of how we should think of neural network interpretability. The content will be rather handwavy and high-level. However, I think the field could make concrete updates wrt research directions if people adopt this framing.
I’m including the original handwritten notes this is based on as well, in case the format is more intuitive to some (also because I’m too lazy to type everything out after having scribbled a bunch of notes during my flight to SF yesterday).
Neural networks can be represented as more compressed, modular computational graphs

Compressibility
I am not claiming that for all sensible notions of “effective dimensionality,” SOTA networks have more parameters than “true effective dimensions.” However, what counts as dimensionality depends on what idealized object you look for in the mess of tensors. For many questions we want to answer via interpretability, there will be fewer dimensions than the number of parameters in the model. Ultimately, compression is about choosing some signal you care about and throwing away the rest as noise. And we have a good idea of what signals we care about.
Modularity
Adopting the analogy of binary reverse engineering, another desideratum is modularity. Why is a human-written Python file more “interpretable” than a compiled binary? The fact that the information has been transformed into text in some programming language is insufficient. For instance, look at minified and/or “uglified” javascript code - this stuff is not that interpretable. Ultimately, we want to follow the classical programmer lore of what makes good code - break stuff up into functions, don’t do too many transformations in a single function, make reusable chunks of code, build layers of abstraction but not too many, name your variables sensibly so that readers easily know what the code is doing.
We’re not in the worst-case world
In theory, interpreting neural networks could be cryptographically hard. However, due to the nature of how we train ML models, I think this will not be the case. In the worst case, if we get deceptive AIs that can hold encrypted bad programs, there is likely to be an earlier stage in training when interpretability is still feasible (see DevInterp).
But there are many reasons to predict good modularity and compressibility:
We know the shape of the training distribution/data and already have a bunch of existing good compressions and abstractions for that data (human concepts)
We impose many constraints and a strong prior on the shape of the function being implemented via the neural network architecture and other hyperparameter choices
We can probe the internals of models to see intermediate representations, get gradients via backpropagation, etc.
The world is modular. It’s helpful to think in terms of higher-level modular abstractions and concepts
Modular (either parallelized, such that they can be learned independently, or composed in series in a way that they incrementally improve performance as a function is added to the composition) algorithms are easier to learn via any greedy algorithm that is not simply searching the full space of solutions, but also using a local heuristic, e.g., SGD/GD.
A compressed, modular representation will be easier to interpret
What does it mean to interpret a model? Why do we want to do this? I think of the goal here as gaining stronger guarantees on the behavior of some complex function. We start with some large neural net, the aforementioned bundle of inscrutable float32 tensors, and we want to figure out the general properties of the implemented function to validate its safety and robustness. Sure, one can test many inputs and see what outputs come out. However, black-box testing will not guarantee enough if the input that triggers undesirable behavior is hard to find or from a different distribution. The idea is that a compressed, modular representation will enable you to validate important properties of the network more efficiently. Perhaps even we can extract objects suitable for heuristic arguments.
An information-theoretic framing
One way to look at modern neural network architectures such as transformers is as a bunch of information-processing channels, each reading and writing to some global state information. To understand the channels, we want to know what distribution of data they operate on, what information they process and ignore, and how it is transformed. Contrast this with many current approaches to interpretability, for example, Sparse Coding, when we just take a bunch of outputs from such a channel (the intermediate activations) and try to find an optimal encoding given some prior we think sounds suitable (e.g., sparseness). However, the object we are analyzing has not been optimized to maximize information transfer between itself and a human trying to interpret it. Rather, it fits into a larger system with other components reading and post-processing the output. To figure out the optimal representation, we should consider this.
A concrete proposal

On a high level, the idea here is we:
Segment weight space (many techniques possible)
Look at each part as a black box function/communication channel that operates on some global state (but only looks at a subset of the available information) and compress the input-output relationship using our knowledge of the input/output activation distributions on the training data distribution + gradients
Reconstruct a compressed computational graph
Sample which nodes maximally activate in different situations / sample the behavior of the compressed system given different internal states
Basic version
In a transformer, the global state information being passed around is the residual stream. We can segment the model into weight chunks, given our knowledge of the architecture - one possible segmentation is breaking down into blocks and then breaking each block into separate attention heads and the MLP layer.
Then, for each such block of weights, we examine it separately as an information processing channel that operates on the global state. In particular, we try to find a principal subset of information that this channel “cares about” so that it can be modeled as a compressed object. For instance, we can try to linearize the block using gradient information and then find a low-rank representation of the linearized channel that operates on a smaller subspace of the residual stream embeddings and writes to a smaller subspace. The usefulness of thinking in these terms is that we can try to find principal bases for the residual stream that are channel-dependent. Given the input, they maximize the extent to which the channel's output can be explained (on the data distribution).
So now we have a representation of the model as a bunch of information processing channels that only care about some subset of the global state, and we know what subsets they care about. We can then do two operations:
See how the subsets line up between the outputs of one channel and the inputs of other channels to find connected communication components
See which channels are used given different types of data to discover circuits via sampling
How does interpretability fit into AI safety?
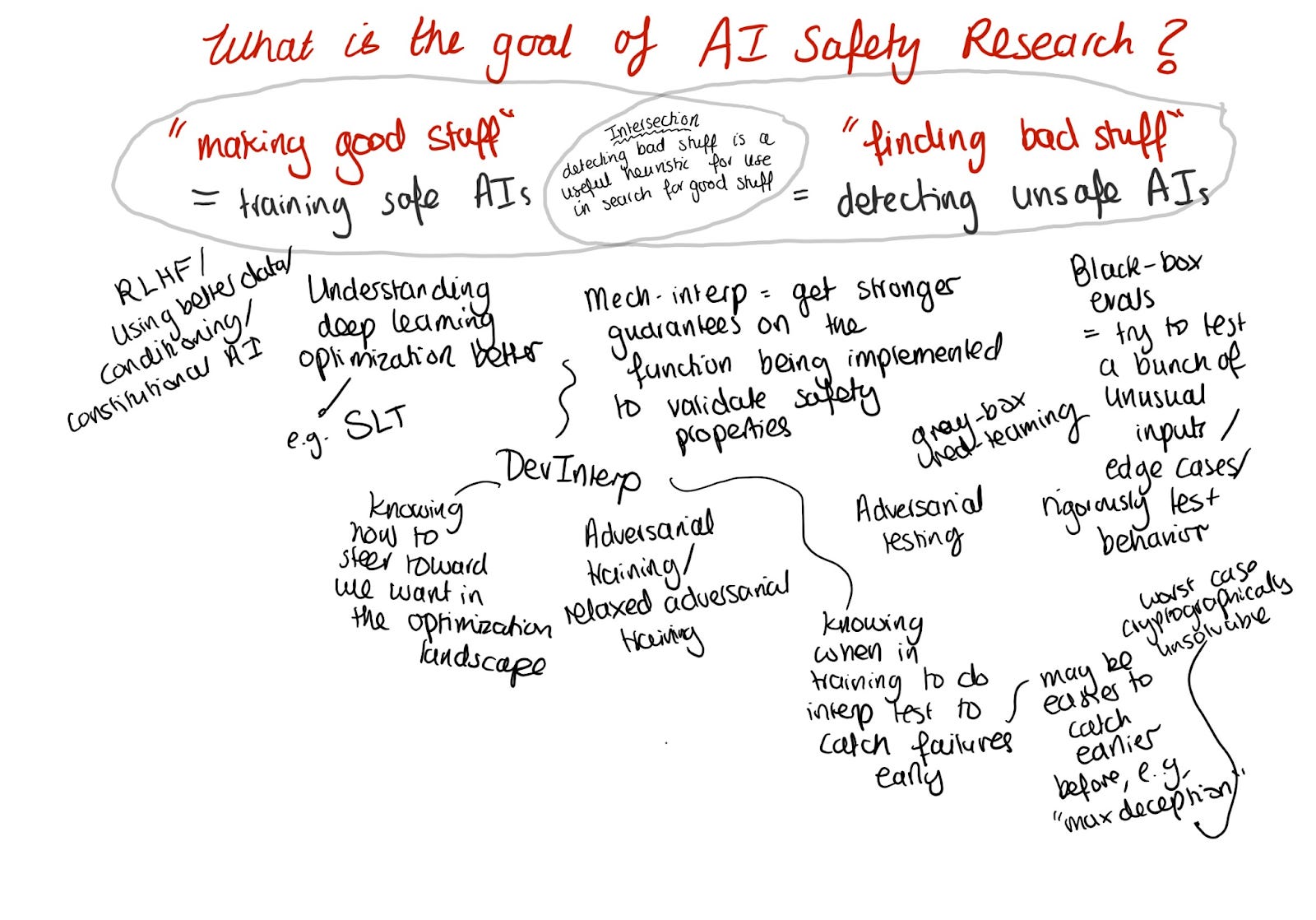
I like to simplify AI safety research agendas into two categories - “making good stuff” and “finding bad stuff.” As banal as this sounds, asking yourself how your proposed idea relates to these is helpful.
Most interpretability research falls under the “finding bad stuff” category - we want to detect dangerous capabilities or predict bad out-of-distribution behavior when we cannot test every possible input.
A category of good & bad stuff I think might be particularly useful to find is emotional/psychological properties of the agent that the LLM is currently emulating the token-generation of. Things like deceitfulness, anger, criminality, hate on the bad side, or helpfullness, honesty, harmlessness, and being an assistant on the good side.
I'm a little puzzled by the references to cryptographic concealment above. Interpretablity is looking into the LLM. The LLM has no fixed motives (other than to predict the next token). It has no inherent interest in deceit. Deceit, and similar motives, are properties of agents that the LLM may simulate. For the LLM to learn an encrypted or even intentionally obfuscated algorithm, the LLM would need to be consistently modeling the same deceitful agent (or at least, sufficiently similar deceitful agents) with the same motives for a significant length of SGD or RLHF training. That agent would then need to be a) situationally aware that it was inside an LLM being trained, b) understand the capabilities of interpretability, and c) be able to do sufficient mental gymnastics to gradient-hack the SGD or RLHF learning process to make it learn a specific encrypted algorithm, while d) doing this in a consistent pattern across training run batches. Or else we would need to be doing RL training and interpretability in a combination that strongly positively rewarded deceit while simultainous penalizing deceit in a manner proportionate to how interpretable it is, thus giving a continuous gradient to follow towards less interpretable deceit. The former seems highly implausible to me (especially requirements c) and d)), and the latter would be a obviously very dumb thing for us to do, so let's not.
The most obvious moral to me here is: don't simulate a lot of deceitful agents during your RL training phase (also, don't give them a scratchpad that lasts across training batches), and don't implement this policy in a way that gives a gradient trail leading towards less and less interpretable deceit.